Task: Assign a discrete label from a fixed set of categories to an input image.
Why not hard-code?: No explicit algorithm exists to programmatically recognize objects (e.g., "cat") from raw pixels. We must use a data-driven approach:
- Collect labeled dataset
- Train a classifier using ML
- Evaluate on unseen test data
Nearest Neighbor & K-Nearest Neighbor (KNN)
How it works
- Memorize all training images & labels.
- For a test image, compute distance to all training samples.
- Predict label of the most similar example (
K=1) or majority vote amongKclosest (K>1).
Distance Metrics
- L1 (Manhattan): $d_1(x,y) = \sum_i |x_i - y_i|$
- L2 (Euclidean): $d_2(x,y) = \sqrt{\sum_i (x_i - y_i)^2}$
- Note: L1 and L2 can yield identical distances for geometrically different points in pixel space.
Complexity & Limitations
- Training: $O(1)$ (just store data)
- Prediction: $O(N)$ where N = training set size
- Critical flaw: Pixel-wise distance is not semantically meaningful. A 1-pixel shift, occlusion, or color tint can make vastly different images appear equally "close" in pixel space. Thus, KNN on raw pixels is rarely used in practice.
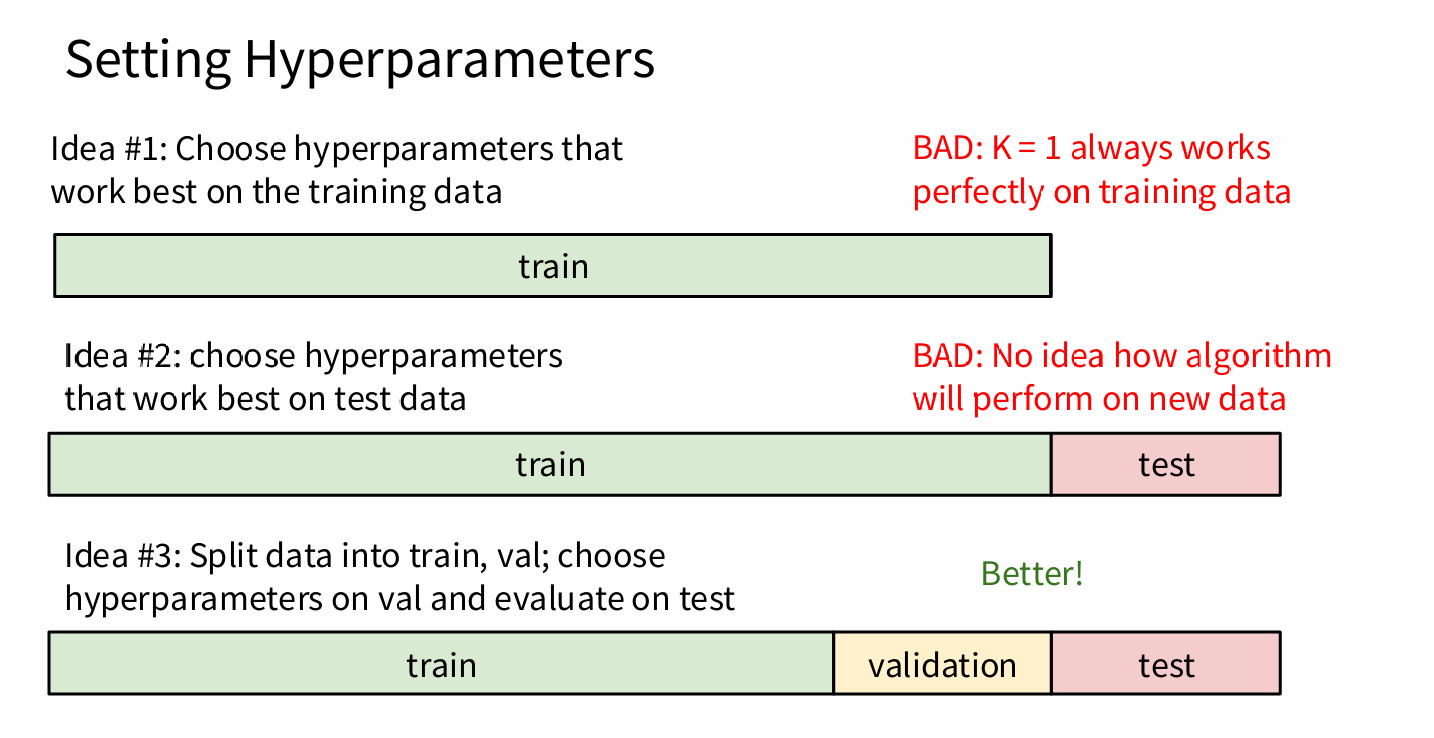
Hyperparameters & Tuning Strategy
- Hyperparameters: Algorithm-level choices not learned from data (e.g.,
K, distance metric). - Bad Practices:
- Tune on training data → Overfits (
K=1always gives 0% train error) - Tune on test data → Leaks evaluation info; no idea of real generalization
- Tune on training data → Overfits (
- Correct Practice:
- Split:
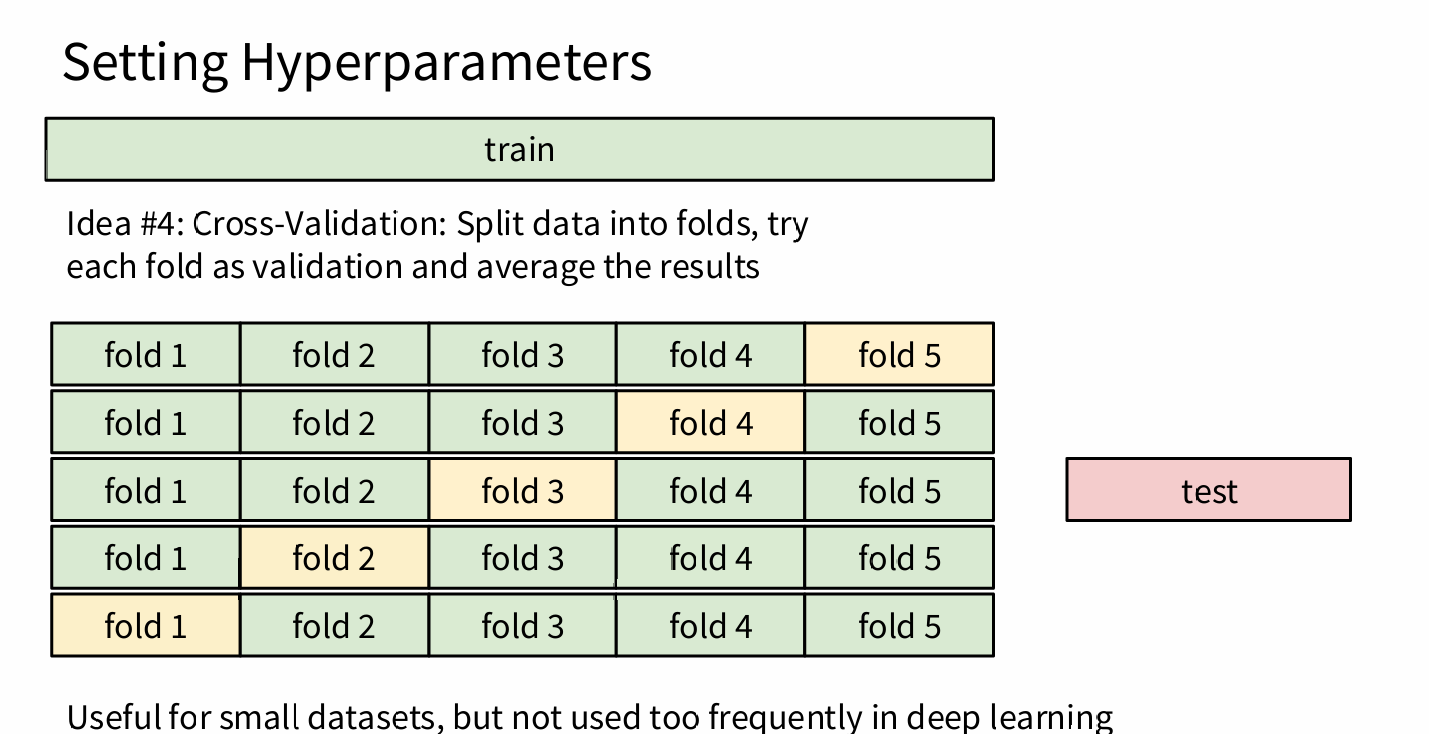
Train→ fit model |Validation→ tune hyperparameters |Test→ final evaluation (use only once!) - For small datasets: Cross-Validation (e.g., 5-fold) to average performance and reduce variance.
- Split:
Linear Classifiers
Instead of memorizing data, learn a fixed set of parameters:
$$ f(x, W) = Wx + b $$
- $x$: Flattened image vector (e.g., $3072 \times 1$ for CIFAR-10)
- $W$: Weight matrix ($C \times D$, $C$=classes, $D$=features)
- $b$: Bias vector ($C \times 1$)
- Output: Raw class scores (logits)
Interpretations
- Visual: Each row of $W$ acts as a template. High score ≈ high template match.
- Geometric: Defines linear decision boundaries (hyperplanes) in feature space.
- Limitation: Can only model linearly separable data. Fails on complex patterns (e.g., concentric circles, XOR-like distributions).
Softmax Classifier & Loss Function
Softmax Function
Converts raw scores to probabilities:
$$ P(y=j \mid x) = \frac{e^{s_j}}{\sum_{k=1}^{C} e^{s_k}} $$
- Ensures $P \geq 0$ and $\sum P = 1$
Cross-Entropy Loss (Negative Log-Likelihood)
$$ L_i = -\log P(y_i \mid x) = -\log\left(\frac{e^{s_{y_i}}}{\sum_j e^{s_j}}\right) $$
- Goal: Minimize loss ⇔ Maximize probability of the correct class.
- Loss Bounds:
- Minimum: $0$ (perfect confidence in correct class)
- Maximum: $\infty$ (zero probability for correct class)
- At random initialization: All scores ≈ equal → $L_i \approx \log(C)$(e.g., $\log(10) \approx 2.3$ for CIFAR-10)
Key Takeaways
- KNN is intuitive but impractical for raw image pixels due to $O(N)$ inference and poor semantic distance metrics.
- Linear classifiers introduce parameterization, enabling fast inference and learnable decision boundaries.
- Softmax + Cross-Entropy provides a probabilistic, differentiable framework for multi-class classification.
- Proper data splitting (
train/val/test) and hyperparameter tuning are foundational to reliable ML workflows.