StableVLA: Towards Robust Vision-Language-Action Models without Extra Data
Paper: arXiv: 2605.18287
Code: Github
Project: website
Model: HuggingFace
Motivation
Existing Problem
Existing VLA model can achieve excellent performance rely on carefully designed test environments with controlled and idealized visual conditions. In contrast, real-world robotic deployment inevitably involves visual degradations such as sensor noise, motion blur, or weather-induced disturbances, the performance will be loss.
Existing Litmation
- First, simulating the infinite combinatorial space of real-world corruptions is computationally prohibitive.
- use simulating the visual degradations case is infinite, it cost much!
- Second, training with augmented data often induces the memorization of specific noise patterns rather than the learning of robust invariant features, which limits generalization ability to unseen corruptions.
- use data to learn its patterns it can get a good generalization!
Method
IB-Adapter
IB-Adapter: An adapter module based on Information Bottleneck(IB)
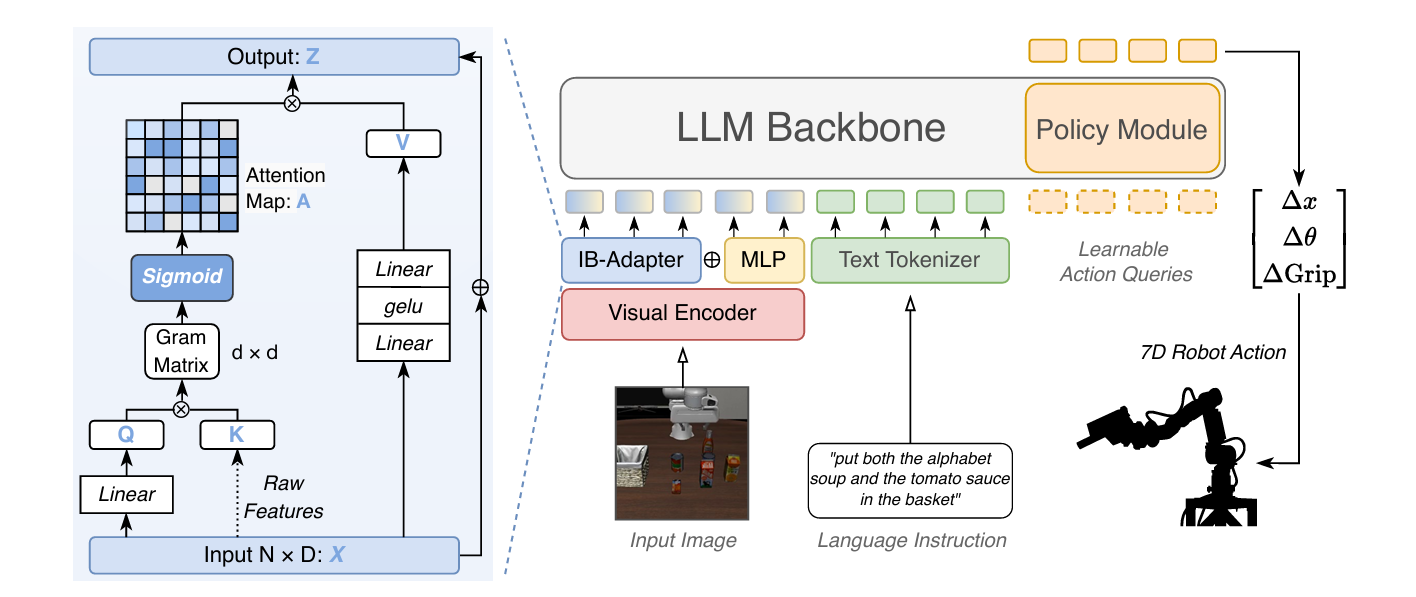
Core:
modality alignment problem modeling to IB optimization:
$$ \min_{p(z|x)} \mathcal{L}_{IB} = I(X; Z) - \beta \cdot I(Z; S) $$
- Compression $I(X_v; Z)$ Sigmoid
- Prediction $I(Z; S)$
Fused IB-Adapter
Make sure robustness and fine-grained control trade-off, here is dual-path fusion architecture:
$$ Z = MLP(X) + tanh(λ) · IBAdapter(X) $$
| Feature | Description |
|---|---|
| Data-efficient | No additional noise data required for training; zero-shot generalization to unseen noise |
| Parameter-efficient | Adds only <10M parameters with <2% computational overhead |
| Plug-and-play | Can be seamlessly inserted into the vision-language projector position of any VLA model |
| Theoretically-grounded | Grounded in the Information Bottleneck (IB) principle, with a clear information-theoretic interpretation |